PostgreSQLなど既存のRDBで、類似検索と概念分類を実現します
ConceptMiner Concept Indexは、PostgreSQLなどの既存のリレーショナル・データベース(RDB)に、概念的な類似検索機能を追加するための仕組みです。
ベクトル・データベースやグラフ・データベースを新たに導入することなく、現在利用しているRDBの中で、VoCデータ、問い合わせ履歴、自由記述アンケート、営業メモ、案件概要などを、意味的に近いグループとして抽出できるようにします。
Concept Indexの仕組み
ConceptMinerの概念構造モデルは、GNG+MSTテクノロジーに基づいています。
GNGは、教師なし機械学習によって、意味的・概念的に類似するデータを複数のノードに割り当てます。さらに、各ノードは互いの類似度に応じてエッジで接続され、トポロジカルなネットワークを形成します。
Concept Indexでは、この概念構造モデルを利用して、データベース内の各データレコードに対応するノード番号を付与します。あわせて、ノード同士の近傍関係を表すテーブルをRDB内に追加します。
これにより、RDB内の各レコードは、単なるIDやカテゴリではなく、「どの概念ノードに属しているか」という情報を持つようになります。
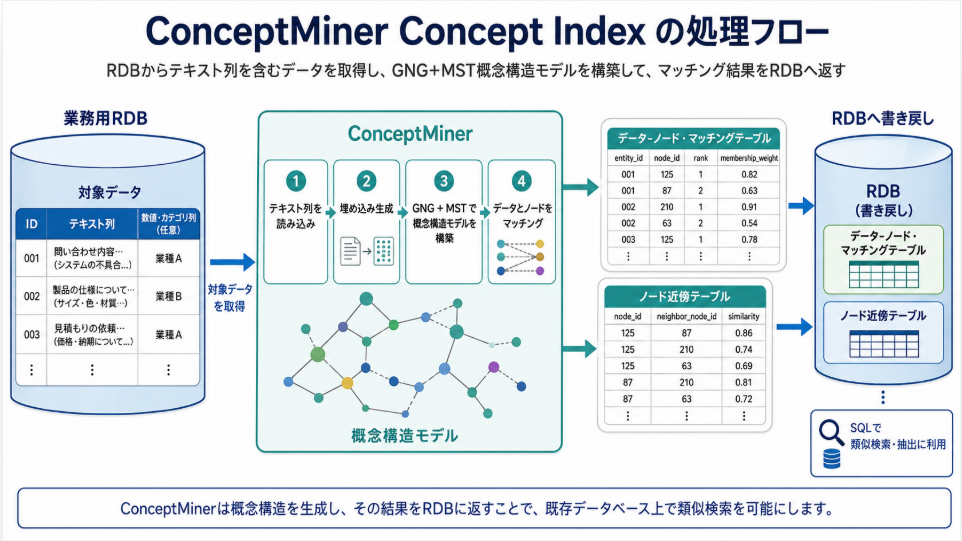
CRDB内で類似データを抽出する流れ
ConceptMiner Concept Indexを利用すると、次のような検索が可能になります。
データベース内の任意のデータレコードを選択するか、任意のテキストを入力すると、ConceptMinerがそれに対応するノード番号を推定します。
その後、同じノード番号が割り当てられている他のデータレコードをRDBから抽出します。さらに必要に応じて、近傍ノードに属するデータレコードも抽出できます。
これが、ConceptMiner Concept Indexによって、通常のRDB内で類似検索を実現する基本的な仕組みです。
この方式では、1件ずつ全データレコードとの距離を計算するのではなく、あらかじめ構築された概念ノードと近傍関係を利用して、類似するデータ群を効率的に抽出します。
ピンポイント検索よりも、概念的セグメント抽出に強い
同じノードに属するデータレコードの集合内で追加の距離計算を行えば、選択されたデータレコードに最も近いデータレコードを探すことも原理的には可能です。
ただし、ConceptMiner Concept Indexの第一の目的は、RAGのように入力文に最も近い文書を1件ずつ探すことではありません。
むしろ、意味的に近いデータ群や、概念的に類似したグループを抽出することに適しています。
たとえば、次のような用途に利用できます。
- VoCデータから、似た不満や要望を持つ顧客群を抽出する
- 問い合わせ履歴から、類似する相談内容のグループを発見する
- 自由記述アンケートから、回答者の関心や不安のまとまりを見つける
- 営業メモから、似た案件や商談パターンを抽出する
- 案件概要から、類似案件の集合を把握する
Concept Indexは、単なるキーワード検索では見つけにくい「意味の近さ」や「概念的なまとまり」を、RDB上で扱えるようにする仕組みです。
ベクトル・データベース、pgvectorとの違い
類似検索を実現する代表的な方法には、ベクトル・データベースやpgvectorがあります。
ベクトル・データベースは、従来のRDBとは別に、ベクトル検索専用のデータベースを用意する方法です。高精度な類似検索に適していますが、既存DBとは別の検索基盤を運用する必要があり、システム構成や管理コストが大きくなりやすいという課題があります。
pgvectorは、PostgreSQLにベクトル検索機能を追加する拡張機能です。既存のPostgreSQL上でベクトル検索を行える点が大きな利点です。ただし、基本的にはベクトル間の距離計算に基づくTop-K検索であり、大規模データでは検索速度やインデックス容量、PostgreSQL側の負荷を考慮する必要があります。
ベクトル・データベースやpgvectorでは、高速化のために近似近傍探索用のインデックスが利用されます。これにより検索速度は向上しますが、一般に検索精度、速度、保存容量の間にはトレードオフが生じます。
これに対して、ConceptMiner Concept Indexは、データレコード同士を直接1対1で比較するのではなく、数百から数千程度の概念ノードと全データレコードとの対応関係を利用します。
そのため、個別レコードのTop-K検索というよりも、「入力テキストや選択レコードが属する概念的セグメントを抽出する」ことに適しています。
結果として、Concept Indexは軽量で説明性の高い類似検索・概念分類を、既存RDB内で実現することを目指しています。
比較表
| 項目 | ベクトルDB | pgvector | Concept Index |
|---|---|---|---|
| 外部DB導入 | 必要 | 不要 | 不要 |
| 既存RDB内運用 | 弱い | 強い | 強い |
| 個別Top-K検索 | 高い | 高い | 追加距離計算なしでは粗い |
| セグメント抽出 | 別途設計が必要 | 別途設計が必要 | 得意 |
| 説明性 | 低め | 低め | 高い |
| 保存量 | 大きくなりやすい | 大きくなりやすい | 小さくできる |
| 初期開発 | 中〜大 | 中 | 中 |
| 運用コスト | サービス課金・別DB管理 | PostgreSQL負荷 | PostgreSQL負荷+更新処理 |
| ユーザーへの説明 | AI検索基盤 | PostgreSQLのベクトル検索拡張 | RDBで類似検索+概念分類 |
ConceptMiner Concept Query
自然言語で、概念的セグメントを抽出する予定機能
ConceptMiner Concept Indexの今後の拡張機能として、ConceptMiner Concept Queryを計画しています。
Concept Queryは、GNG+MSTによって得られた説明性の高いセグメンテーションを利用し、自然言語による複雑なデータ抽出を可能にする機能です。
たとえば、次のような表現で指示するだけで、該当するデータ群を抽出できるようにすることを目指しています。
- 収益性が高いが、離反リスクも高い顧客層
- 価格感度が低く、プレミアム志向の強いグループ
- 問い合わせが多いが、満足度も高いセグメント
- 新商品に反応しやすいが、継続率が低い層
- 少数だが、売上貢献が大きい特殊な顧客群
これは、AIが単にSQLを自動生成するだけの仕組みではありません。
事前に構築された概念的セグメントを利用することで、通常のSQLだけでは表現しにくい「意味的に近い顧客層」「特徴が似ている案件群」「行動パターンが近いデータ群」を、日常業務の中で素早く抽出できるようにすることを目指しています。
将来計画
データマイニングとの融合
当面のConceptMiner Concept Indexは、テキスト列の埋め込みをもとに概念構造モデルを構築し、テキストデータの類似検索、すなわち概念検索を行う設計です。
将来的には、テキストだけでなく、数値データやカテゴリ値を含む定量データからも概念構造モデルを構築できるようにする計画です。
これは、従来「データマイニング」と呼ばれてきた領域に近いものです。
マインドウエア総研は、過去25年以上にわたり、SOMアプローチによるデータマイニングに従事してきました。その経験から、データマイニングは本来、科学的な探求行為に近く、通常のビジネス現場で日常的に実践することが非常に難しいということを痛感しています。
そこで、ConceptMinerでは、AIによってマイニング・プロセスそのものを支援し、データマイニングによって得られる有用なセグメンテーションを、日常業務で利用可能な形に変換することを目指しています。
将来的には、テキストデータ、数値データ、カテゴリデータを統合し、RDB上で概念的なセグメントを扱えるデータ活用基盤へと発展させていく計画です。
納品形態と導入・インストール手順
限定予約販売
ConceptMiner Concept Indexは、限定予約販売を開始しています。
通常年間ライセンス料:400,000円
予約特価:260,000円(消費税別)
※予約特価は初年度のみに適用されます。
※対象データベースはPostgreSQLです。その他のデータベースについては個別にご相談ください。